| Chapter 1. Introduction | ||
|---|---|---|
 | 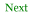 | |
| Chapter 1. Introduction | ||
|---|---|---|
| | | |
Table of Contents
This document refers to the XSLT implementation, available
from schematron.com. I never
found this architecture simple, but I have come to understand it
over time. The sequence is that the constraints(rules) are specified
in an xml file (call it input.sch) which is the
schematron file. This is processed using an XSLT tranform to
generate another XSLT stylesheet, which is then used to process the
actual input document. The output of this transform is a report
(which I find most useful in XML, possibly the Schematron Validation
Report Language, annex D of 2),
and which tells you whether the input file is valid!
See Figure 1.1, “Schematron architecture”, for a diagram illustrating this
process. Processing the Schematron file with
iso_svrl.xsl produces an interim stylesheet
(unnamed and only required temporarily). This is used to transform
the input file, generating the validation
results. iso_svrl.xsl in turn imports
iso_schematron_skeleton.xsl, which does most of
the work of generating the interim
stylesheet. iso_svrl.xsl wraps the output of
iso_schematron_skeleton.xsl in the svrl
markup. If you want plain text output, substitute
iso_schematron_skeleton.xsl directly for
iso_svrl.xsl! A very elegant solution.
Let's go over that once more. The first step is to have an XML
instance to validate. That's the input file (say
input.xml). Next, on review you decide you need
to validate some aspect of that file. It could be that every chapter
element has a title element as it's first child. You then start to
write another XML document (the schematron file), say
input.sch, which holds these rules or constraints
(assertions as they are called in the standard). Once all the
constraints have been specified, this schematron file is processed by
an XSLT engine (msxsl, Saxon or libxslt) with an input of
input.sch, using the stylesheet
iso_svrl.xsl, to produce an interim stylesheet
document (say tmp.xsl). This output file is in
the Schematron Validation Report Language (svrl) defined in Annex D of
2. For this document, I've chosen to
use the XSLT 2.0 W3C recommendation.
Next the main input file is processed by the XSLT engine using
the interim stylesheet (input.xml is processed by
tmp.xsl) to check the constraints that you
specified. The resulting report file makes very clear statements about
the input file and its validity to the constraints you specified in
the Schematron file. It either aligns with the constraints you
specified, or it doesn't.
That is the basis of Schematron. As you may imagine, there's a lot more to it, but try and keep that overview in mind as we explore the details.
Since I'm discussing the XSLT implementation, I'm going to assume a reasonable knowledge of XSLT. If you don't, you will soon lose interest in this document. If you want to learn, Google is your friend.
Next. Why would you bother? I.e. why use Schematron at all? Perhaps you're asking what could it be used for? Roger Costello asked that question on the xml-dev list and came up with the following conclusions.
This example will be used in the below discussion:
Example 1.1. General example for Schematron usage
<?xml version="1.0"?>
<Document>
<Classification>unclassified</Classification>
<Para>
One if by land; two if by sea.
</Para>
<Classification>unclassified</Classification>
</Document>
Here are the ways that Schematron is being used today:
Co-constraint checking
In the above example there is a co-constraint between the two Classification values; namely, the two values must be identical.
In general, co-constraints are constraints that exist between data (element-to-element co-constraints, element-to-attribute, attribute-attribute). Co-constraints may be "within" an XML document, or "across" XML documents (intra- and inter-document co-constraints).
Schematron is very well-suited to expressing co-constraints.
Notes:
The term "co-constraint" is a misnomer, as it suggests a constraint only between two items. There may in fact be a constraint over multiple items, not just two items. For example, if there were many Classification elements then we need to check that ALL values are identical.
Co-constraints may exist between XML structure components (elements, attributes) as well as between data values. For example, if Classification has the value "unclassified" then Document must only contain the elements shown above; if Classification has the value "secret" then Document must only contain other elements (not described here).
Cardinality checking
In the above example the cardinality constraint is: the text in the Para element must not contain any restricted keywords. (The keywords may be obtained dynamically from another file.)
In general, cardinality constraints are constraints on the occurrence of data. The cardinality constraints may apply over the entire document, or to just portions of the document.
Schematron is very well-suited to expressing cardinality checks.
Notes:
Cardinality checking encompasses uniqueness checking.
Existence checking is a special case of cardinality checking.
The following example will be used to characterize the next category of Schematron usage:
<?xml version="1.0"?>
<ElectionResults>
<ByPercentage>
<Candidate name="John">61</Candidate>
<Candidate name="Sara">24</Candidate>
<Candidate name="Bill">15</Candidate>
</ByPercentage>
</ElectionResults>
Algorithmic checking
In the above example the algorithmic constraint is: "the election results must add up to 100%" (i.e., 61 + 24 + 15 = 100).
In general, validity of data in an XML instance document is determined not by mere examination or comparison of the data, but requires performing an algorithm on the data.
Schematron is very well-suited to expressing algorithmic checks.
Note:
"Algorithmic checking" may not be the best name for this category. Other names suggested: "Computed value checking", "Formula checking", and "Equation checking".
Author specified error messages
Schematron allows the schema author to write the error messages, thus the errors can be reported at a higher (operational/user) level. The schema author can thus communicate with the user and explain the error in an understandable way and direct the user on how to correct the problem.
External Data Mashups
Data used in Schematron assertions may be dynamically obtained from external files.
Many thanks to the following people for their excellent inputs into creating the above summary.
| Manos Batsis |
| George Cristian Bina |
| Stephen Green |
| Peter Hunsberger |
| Rick Jelliffe |
| Michael Kay |
| Guillaume Lebleu |
| Dave Pawson |
| Bryan Rasmussen |
That list may not be particularly familiar to you, just remember it when you have a validation problem. The general point is that Schematron is flexible and has a high utility.
| | | |
| Preface |  | Chapter 2. Getting Started |